Video tutorials are only available to users logged in to the HG Insights help center. Click here to learn how to create an account in the HG Insights help center.
Pre-requisites:
You have access to the Data Studio
HG Insights's Data Studio, allows users to easily build and edit predictive models and segmentations.
HG Insights’s likelihood to buy (or PQL) models learn from historical patterns to uncover specific behaviors that separate leads who were on the path to conversion from others. HG Insights continuously scores all of your active leads based on their behavior (in-app behaviors, marketing & sales interactions, etc.) to determine which ones are showing a lot of interest or engagement with your product/website/company.
At a high level, the platform allows you to:
create a training dataset from your CRM
understand which events are correlated with conversion
adjust the weights and decay of each event in the scoring
adjust the thresholds between the Likelihood to Buy segment (very high, high, medium, low)
remove some activities from the signals of the model
validate the performance of the model on a validation dataset
preview a sample of scored leads
Now let's get into the details.
Before we start
If you are not familiar with the concept of the Likelihood to Buy model or the different models offered by HG Insights we recommend reading this article.
How to access your Likelihood to Buy model?
Either from your account in app.HG Insights.com > Predictions, click on View model in the Likelihood to Buy section or Data Studio
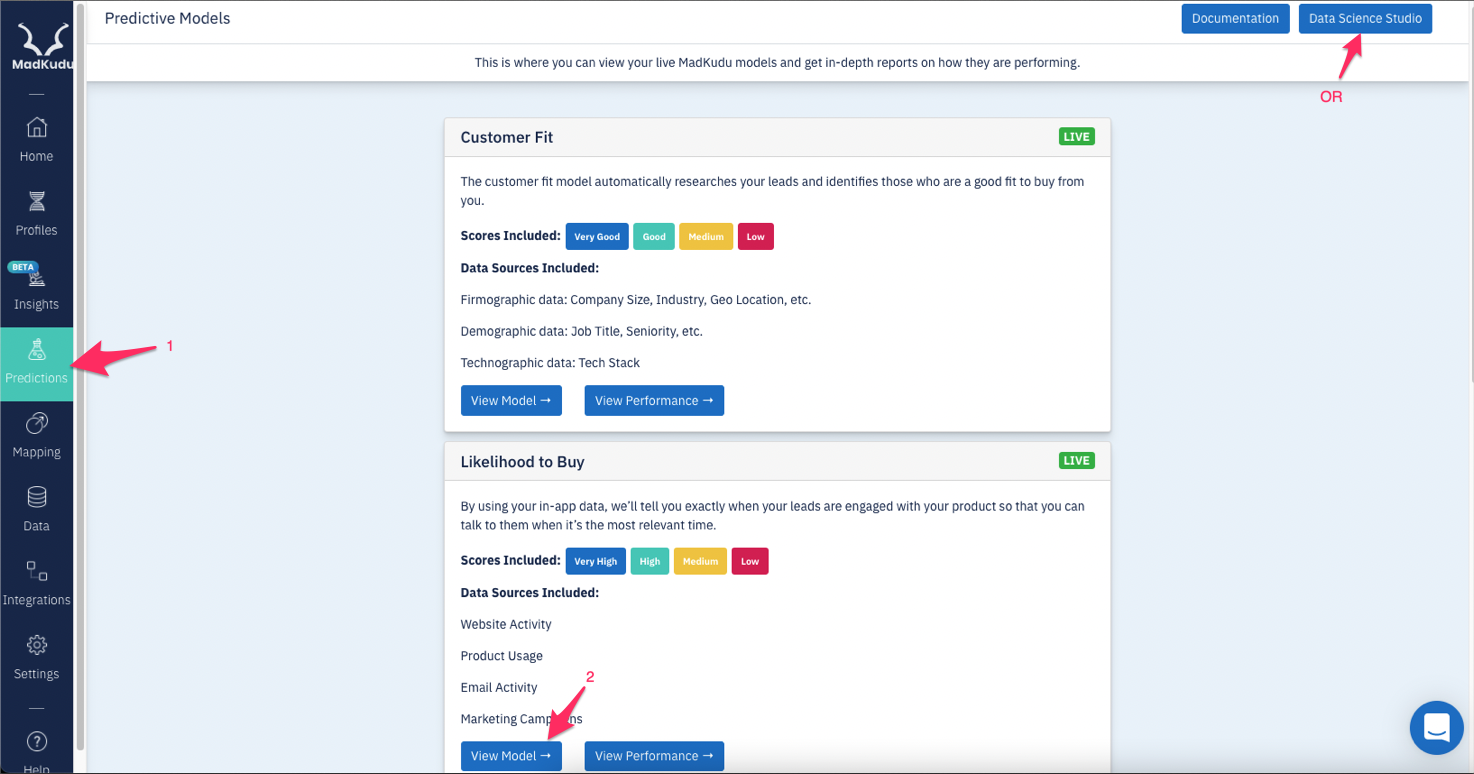
Or directly with the Data Studio URL studio.madkudu.com, you will find the list of models live in your CRM or just draft models.
Likelihood to Buy models are identified with the model type Lead LTB (PQL) or Account LTB (MQA)
Below is a description of each section of the model in the Data Studio.
Overview
In this section, you can
see some quick info on the creation and update date of the model
save notes about the model
quickly access some parts of the model
get some sanity check data about the training and validation datasets that you uploaded (Dataset summary). Learn more about the Likelihood to Buy training and validation dataset.
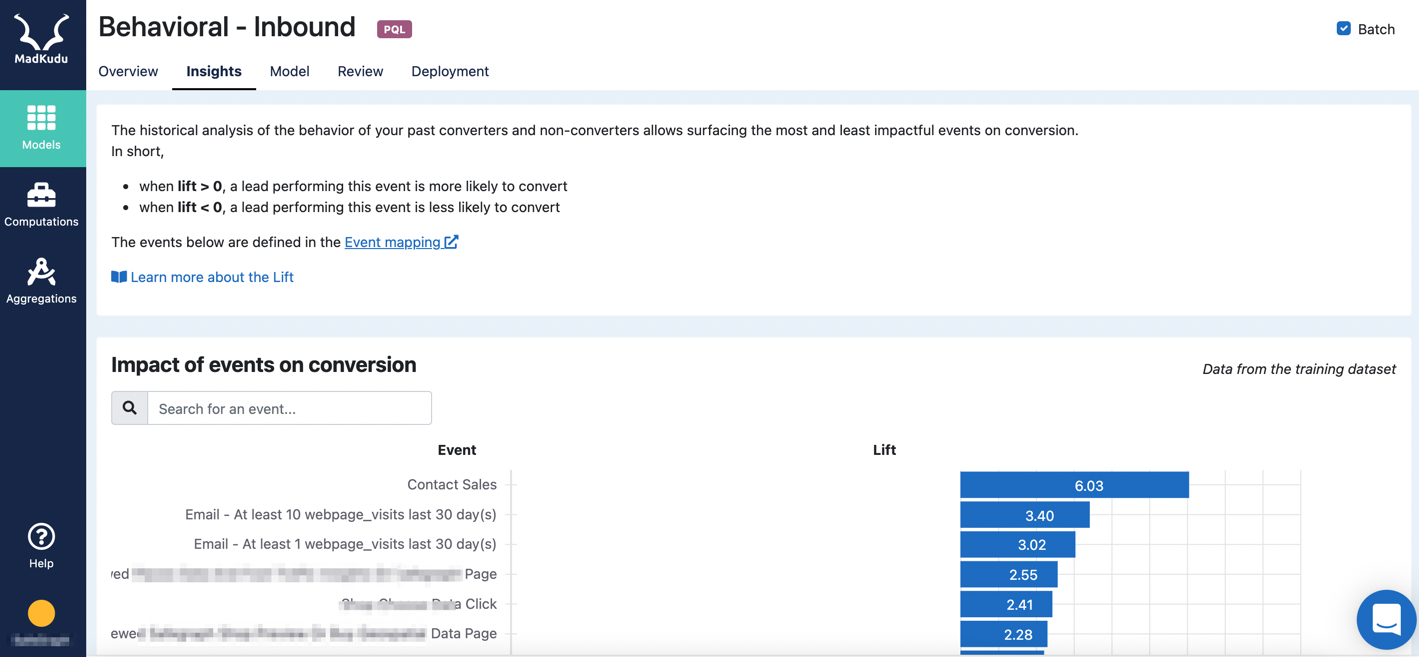
Insights
The Insights tab provides information on how each event is performing compared to one another in terms of correlation to conversion. How to read the Likelihood to Buy Insights graph and tables.
Model
This section regroups all the different parameters which can be changed to configure the model.
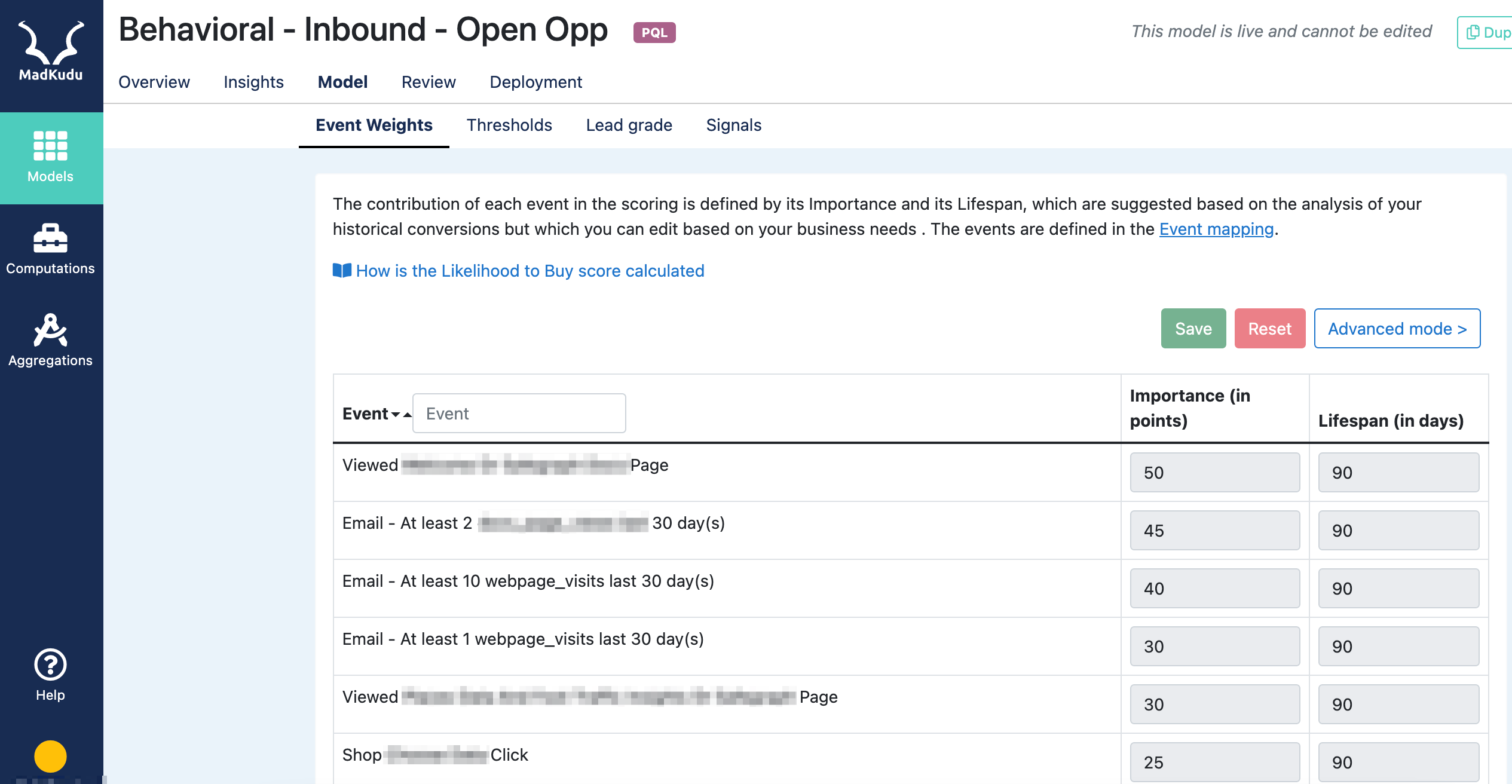
Event weights
The Event weights tab is used to configure the importance (weight of each event) and the Lifespan of the events to use in the model.
HG Insights does not work with default scoring rules but instead automatically suggests custom Likelihood to Buy scoring rules based on the analysis of the behavior of your past conversions.
However, you may want to customize the weight of some events in order to suit your business needs and to improve the performance of the model. See how to edit your Likelihood to Buy scoring model.
Thresholds
Setting thresholds for the different segments would be done in the Thresholds tab. On this page, you are also able to see the performance of the model on the training dataset.
Learn more about how to optimize the performance of a model.
Left graph: total population in the training dataset, scored and their distribution displayed by segment. We want to get close to a distribution of:
~10% very high
~20% high
Right graph: converters in the training dataset, scored and distributed by their segment. We want to have a distribution close to:
very high + high the largest as possible (an "ok" result would be ~ 55%, a really really excellent result would be > 80%), called the "Recall" (your true positives).
low should catch no more than ~10% of the conversions
Keep iterating as needed, the end goal is to achieve the ~20/80 rule of "20% of highly active people account for 80% of people who converted". The thresholds allow us to adjust this distribution, but mostly the weight of each event are fine tuned to improve the performance of the model and get closer to that 20/80 rule

The second metric to look at is the Precision: is the model identifying correctly the leads who convert at a higher rate than others? Ideally, we want to have at least a 10x difference in conversion rate between the very good and the low. This means the very goods will actually have a higher probability to convert than the lows.
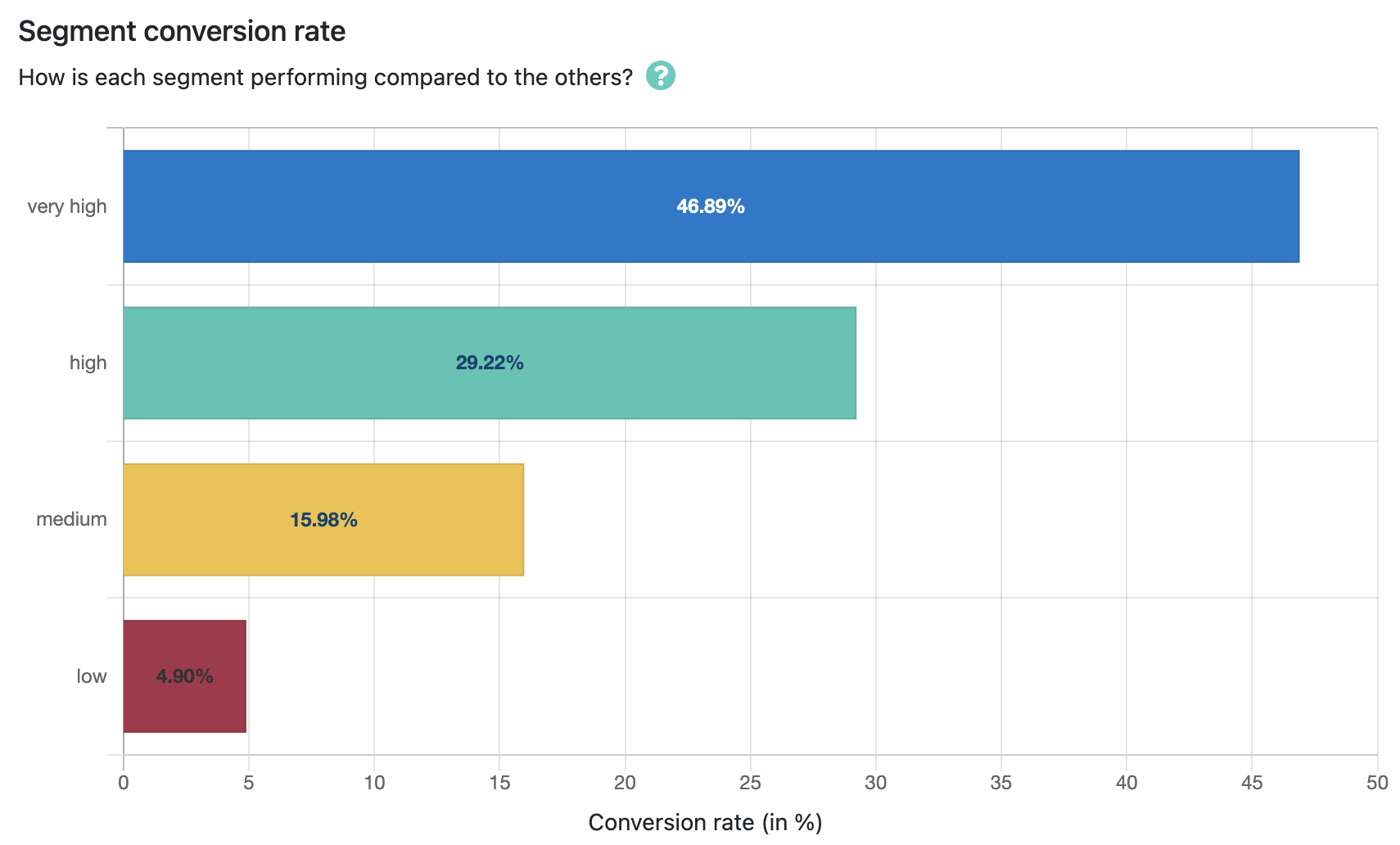
Note: the conversion rates here should not be taken in absolute as the training dataset has been engineered (downsampled) to reach a 20% conversion rate.
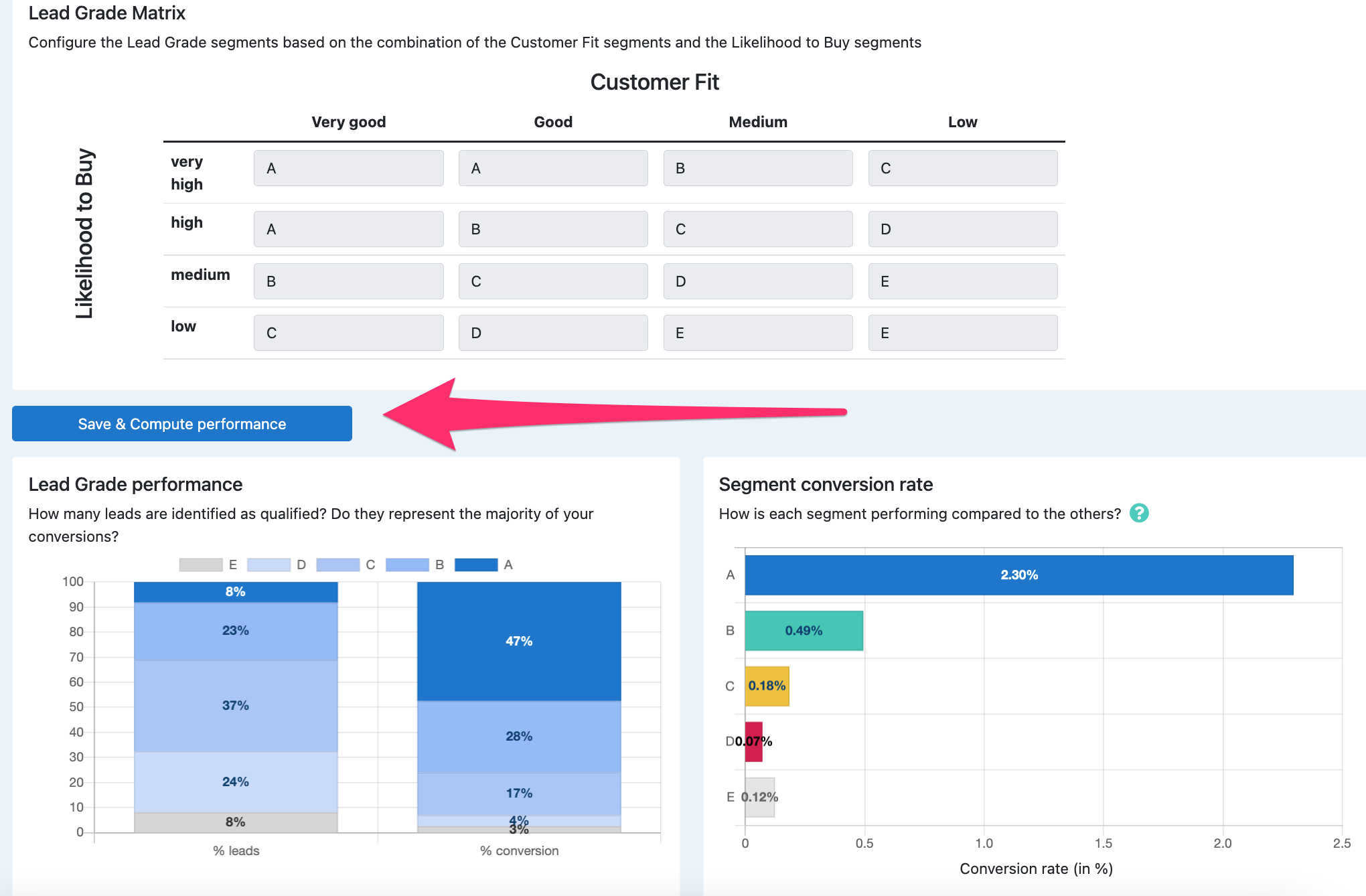
Lead Grade
The Lead Grade is the combination of the Fit score and the Likelihood to Buy model.
The Grade A, B, C, D, or E is defined by the matrix configured in the tab.
Configure this matrix according to how you want your leads scored depending on their combination of fit score and behavioral score.
Usually leads with a grade A & B are qualified and sent to sales team.
Click 'Save & compute performance' to see the performance graphs for this Lead Grade matrix configuration.
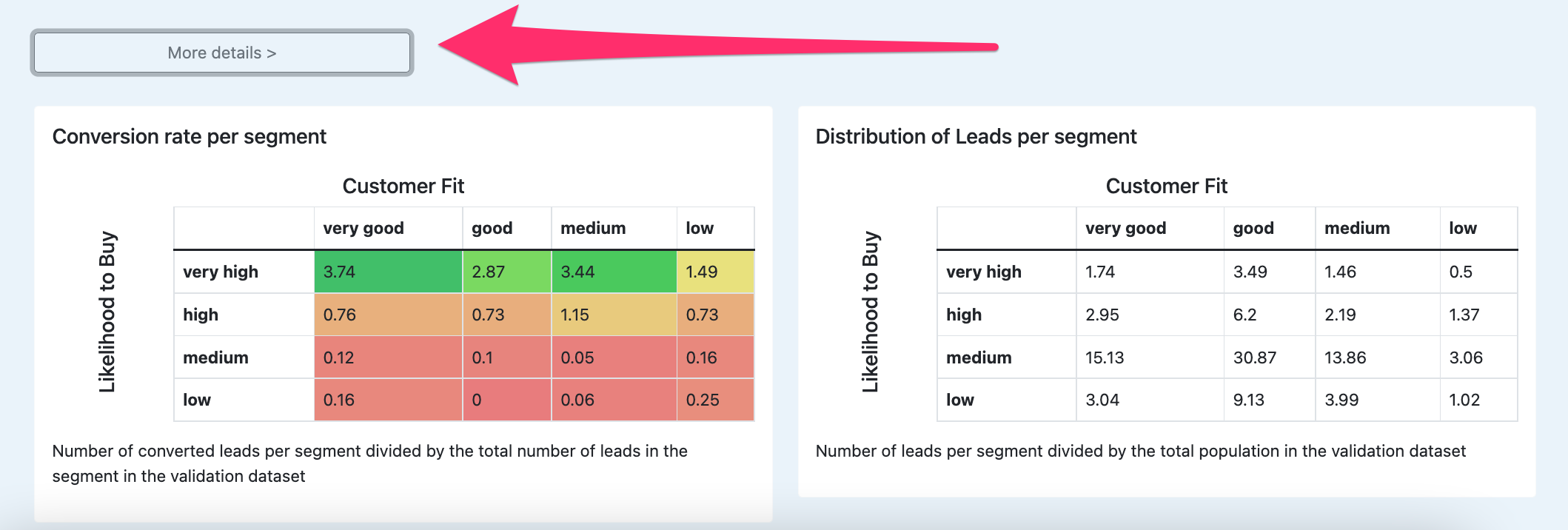
Click 'More details' to view the repartition of your leads in your Lead Grade matrix, and their respective conversion rates.
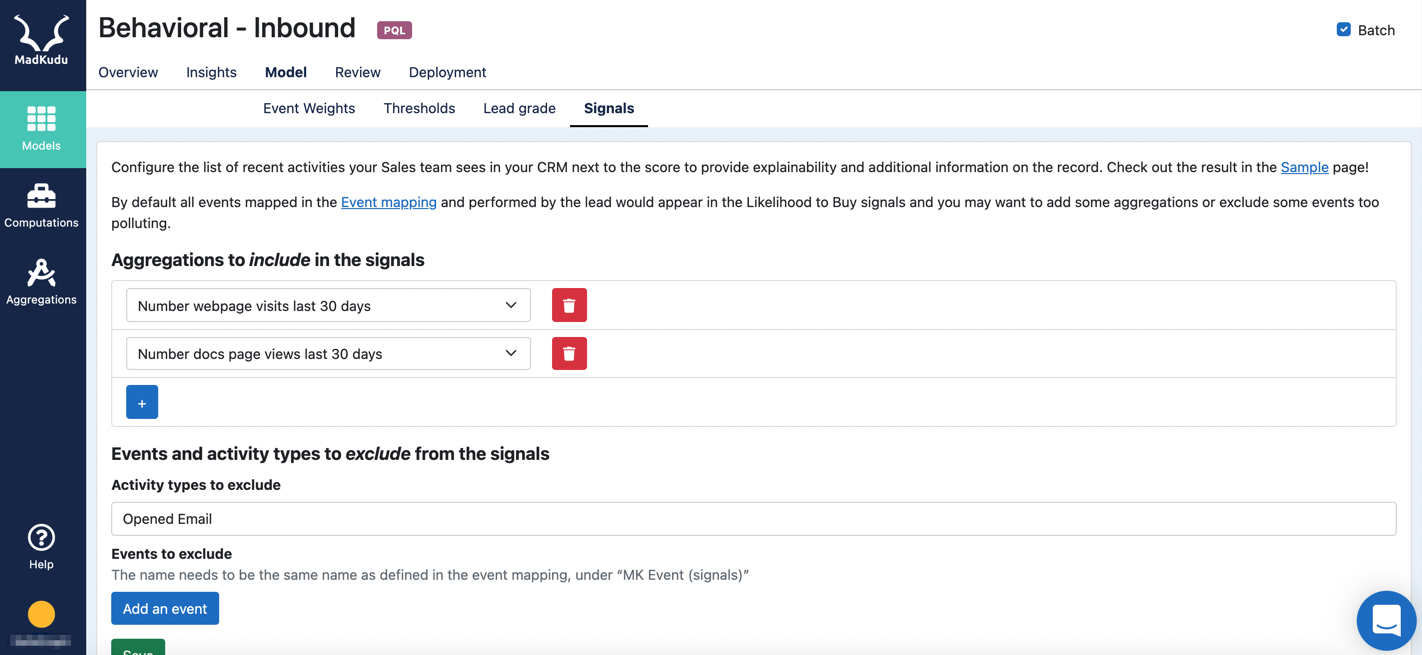
Signals
Every mapped event will appear in the Signals field pushed to your CRM field. However, there are certain events that may not be helpful to show to your Sales team as they evaluate new MQLs, for example: non-user activities.
The Signals tab in the Data Science Studio allows to remove some activity types and events from the Signals displayed to your Sales in your CRM.
Tip
Removing an aggregation or aggregated event from Signals also unlocks it for deletion/renaming in the Aggregations tab.
Review
Sample
Check out a sample of scored leads from the validation dataset in the Sample page. You will find for each email its
score (normalized between 0 and 100)
segment
signals (last activities)
on the date of the validation dataset. What does this mean? To validate the model we "simulate" that we are on a certain date, say Oct, 1st 2021, and look at who are the people who were active and then converted after that date, versus people who were active but didn't convert.
Therefore the score, segment and signals in the Spot check would correspond to the one for this person on Oct 1st, 2021, and not today.
Performance
The Performance tab reflects the performance of the model (similar to the charts in the Thresholds tab) but on the validation dataset.
A model needs to be validated on a validation dataset that does not have any overlapping data with the training dataset. For that, we usually take more recent leads than the training dataset and check the performance of the model on this dataset in the Validation tab. The same metrics of Recall and Precision can be extracted from the graph and a model is "valid" if we are still close to 65%+ Recall and 10x Precision.
Note : "Recall" means the true positives, converters scored with high LTB or very high LTB who converted.
F.A.Q.
What is the difference between the Likelihood to Buy model and PQL model?
None, this is just a different naming that we use. PQL stands for Product Qualified Lead.
How is the graph in the Feature evaluation sorted?
The first event displayed are the ones with enough statistical significance (events done by at least 100 people in the whole population of the training dataset)
Following these are the events with less to no significance (done by 10 to 100 people)
The las events are the ones with no significance (done by less than 10 people)
How are the “Factor loading” values determined? They don’t seem to perfectly correlate with the Lift factor.
Short answer: Combination of statistical analysis and business sense
Long answer:
The platform applies a formula based on the lift and the average number of occurrences per person of that event to define what the score should be
But the weights and decays are adjusted to
improve the performance of the model
match business context and expectations: If the historical data shows that "requested a demo" does not have the highest lift, we would still want to put a heavy weight to make sure the leads requested a demo are flagged a high /very high
Why do some events with negative lift have positive factor loading?
we would assign negative points to negative user actions
we assign low weights to positive user events with a low lift to differentiate people who have done nothing versus people who have performed some activities
If we were to change either the “factor loading” or “decay” input for any of the fields, is there a way to see what the effect would potentially be?
You would see the effect on the Thresholds page overall but not at the event level
Is there a way to see the confidence interval for any of these factors?
Our proxy to have statistical significance is to look at the “Did X”. If Did X >100 -> we assume that we are looking at a population large enough of people who did this event to derive a conversion rate and a lift.
Low sample sizes could cause some inaccuracies (ex. Several factors have -1 lift which is an oddly round number)
Correct, this is why it is possible to also manually change some event weights.
-1 usually means that this event was not performed by any person who converted, and only by non-converters.
On the Review page, why am I getting errors when I try to load a Sample or the Performance of my model?
When you get errors, please don't hesitate to share with us a screenshot or Loom video when that happens to help us fix bugs you may be facing.
Depending on the volume of data to be processed (eg. a large volume of events), our platform can show delays in displaying results. We are working on improving that.
Would validation allow us to see what the effect of changes in the model would be prior to implementing a change?
Not exactly, once you make an update to your model in the Studio, you are able to see how this update to the model affects the performance on the validation dataset only (i.e. a population set different from the population in your live CRM). As such, the Studio allows you to gain insight into how the model scores might change after making updates. This is why we recommend uploading a more recent validation dataset date when working on updates in a duplicate model. Validating on a more recent dataset means that you are looking at data most similar to the data currently in your CRM.
What does “with parameters” mean within the Validation tab?
The parameters are a reminder of the different thresholds set in the Thresholds tab to define the point thresholds that dictate of a lead is very high / high / medium / low.
What if I weigh the behavior side more heavily than fit in the Lead Grade?
Note that the Lead Grade is primarily built from the Matrix of segment, and then the score within the segment is adjusted with the formula weighting the fit and the behavior.
By putting more weight on the behavioral model than the customer fit, you would score higher, within the segment, people more active than more qualified (from a demo/firmo/technographics perspective)
How do we test the impact of making a change?
On the homepage where all of you models are listed, click on "duplicate" the model.
On the duplicated model you can load a new validation dataset (without touching the training dataset) and see how the model performs against another validation dataset.
Seeing the effect of changes of the model prior to implementing this change at a more granular level of which lead will change score is a manual process done outside of the Data Science studio today by our Solution Engineering team but that we want to productize very soon.
Any more questions? Feedback? Please send us an email to product@madkudu.com