The Likelihood to Buy models (at the Lead level, named PQL model, or at the Account level, named MQA model) is built based on behavioral activity analysis of your past prospects and conversions. It analyzes leads and accounts behavior before they converted and compares it to the behavior of non-converters. It uses this comparison to surface if a prospect has a level of engagement similar to someone worth talking to, or if you should send this lead to a nurturing cycle.
To recognize high engagement events versus low engagement events, we need to create a training dataset to train on. The training dataset is built by looking at one or more dates in time, who was active and converted in the next 30 days versus who was active but didn't convert, to understand which events are more likely performed by converters vs non-converters.
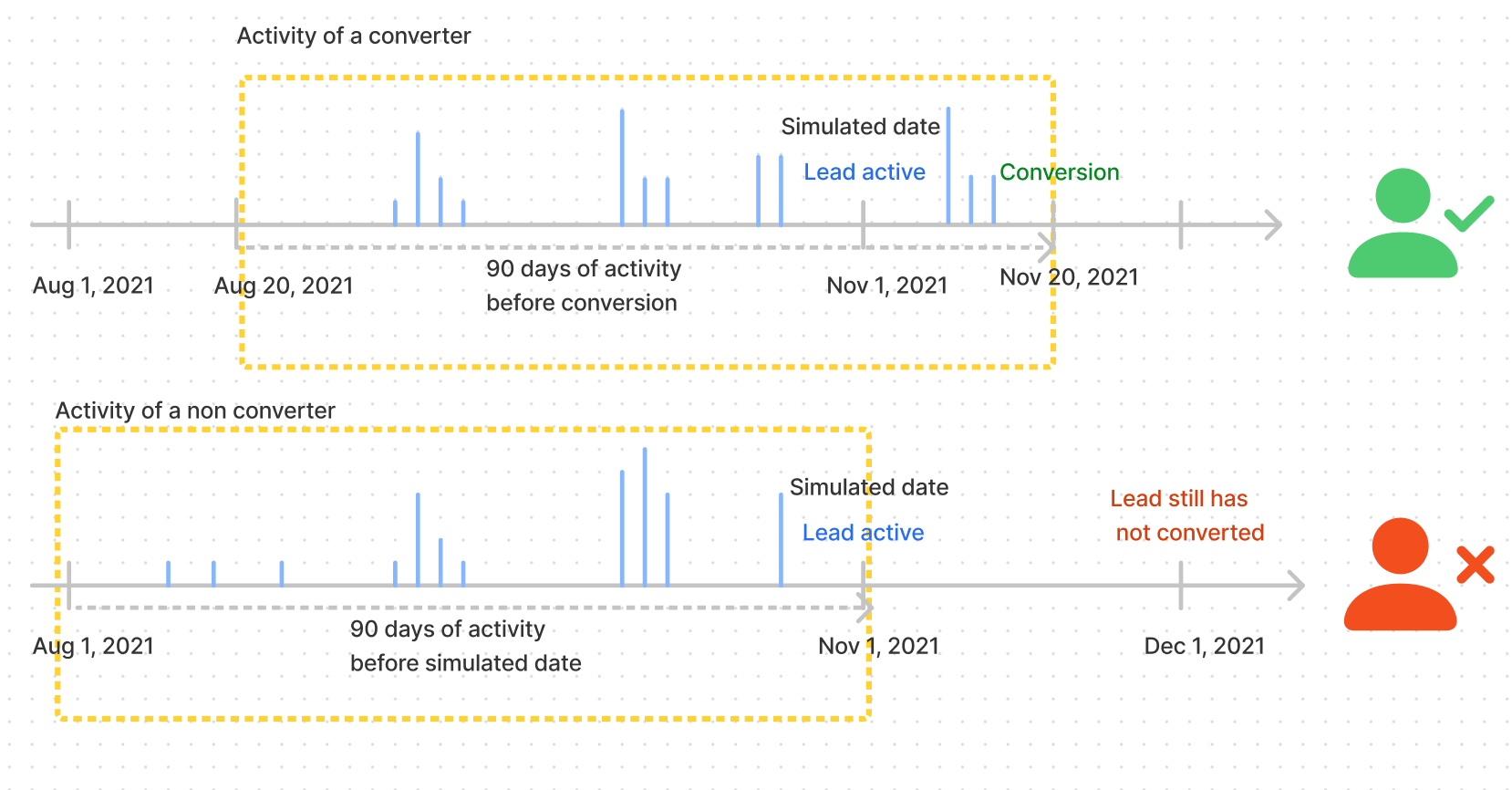
An email is considered active at date X if it performed at least 1 action (ex: log in) within the past 90days.
The exact date that is used to ensure an activity performed by an email is not counted after conversion is the Opportunity Creation Date.
A training dataset is essentially a table with two columns: email which contains the email of the lead, and target with a value of 1 if the lead has converted, of 0 otherwise; and as many observations (rows) as possible.
Sample:
target | |
francis@madkudu.com | 1 |
james@tesla.com | 0 |
john@ibm.com | 1 |
Then we get all the events performed by these people during the 90 days prior to their conversion or prior to the date we are simulating. Example: we simulate we are on Nov 1, 2021 and look at
all the events performed by the people who were active on Nov 1, 2021 and converted in November 2021
all the events performed by the people who were active on Nov 1, 2021 and didn't convert in November 2021.
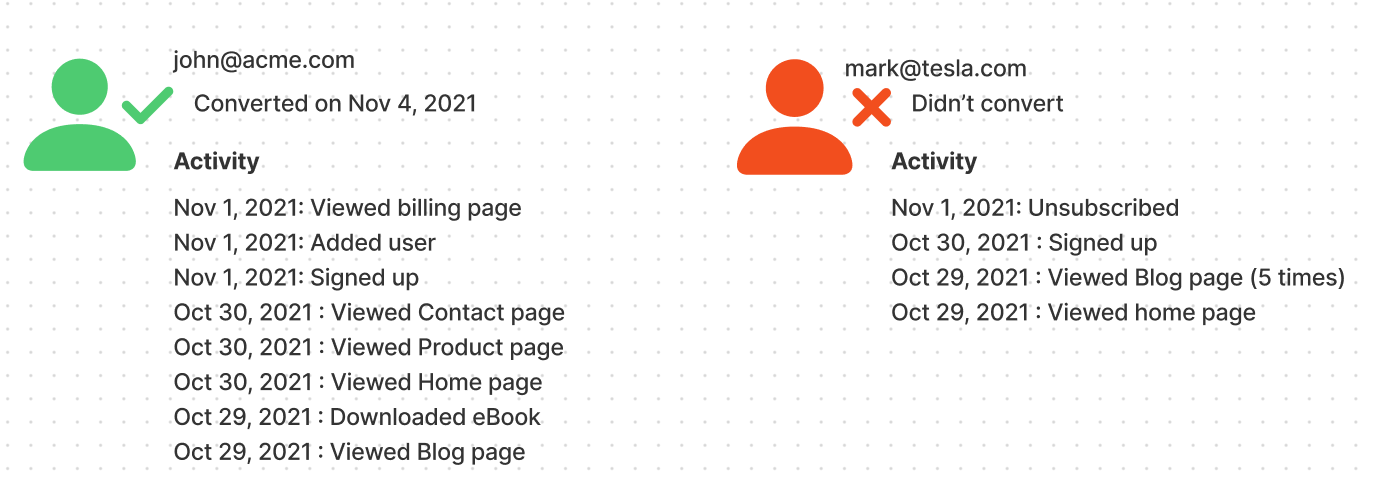
A validation dataset will be needed to validate the model on a different set of leads than the ones it was trained to make sure the model is able to predict conversions. The model will give a score for the leads of the validation dataset, so you can check whether or not the model predicted the right score for those leads.
When to load a training dataset?
You would like to create a new model from scratch.
You would like to see what is the importance of events on different dates.
-> You would load a training dataset either on a duplicate of your live model or on a newly created model.
How to build and load a training dataset?
Well, with HG Insights, it is just a few clicks and no code is needed! You just have to input some parameters and it will create it automatically from your CRM data.
Step 1: Create the training dataset
Go to Data Studio (studio.madkudu.com or app.HG Insights.com > Predictions > Data Studio)
Create a new model (PQL or MQA)
Click on Import data
Configure the following parameters for the training dataset
The training dataset is built from all the leads active on one or more dates. We recommend using dates no older than 6 months from now because HG Insights only stores 9 months of behavioral data and the analysis is always based on the activity of a person during the 3 months prior of the selected date (9 months = 6 months + 3 months). Try this:
Training dataset dates: today - 3 months, today - 4 months, today - 5 months.
If today is Nov 1, 2021, use 2021-08-01, 2021-07-01, 2021-06-01
Simulating more than 1 date allows having more data in the training dataset to increase the statistical significance of the analysis.
Use the date picker but here you only need to select one day per month, which is different from the date picking method used for Customer Fit datasets:
Audience: What is the population of leads you'll want to apply the scoring on? inbound leads? outbound leads? North American leads...etc? Select the audience of leads you'd like to focus on, which is configured in the Audience mapping in the app.
Conversion model: What is the outcome you want the model to predict? leads who would become any qualified opportunity? become paying customers above a certain amount (Enterprise customers)? Use a conversion model name defined in the Conversion mapping in the app.
This decision depends on what you intend to do with this scoring. For example: if you'd like to use the scoring to route your best leads to your Enterprise sales team, then you'd want the model to flag very good the leads who look like your Enterprise customers.
Step 2: Create the validation dataset (optional)
To create the validation dataset, you'd want a more recent dataset. For the validation you can use only 1 date the simulation is made on. We recommend using the following date:
Validation dataset date: today - 2 months.
If today is Nov 1, 2021, use 2021-09-01.
When training a model, use in the validation the same audience and conversion filters as the training dataset to validate the model on the same type of population.
Step 3: Launch the loading of the dataset(s)
To launch the loading, click on Build dataset.
The dataset(s) will be created from our database that stores your relevant CRM and behavioral data. It usually takes about 1 hour but depending on the size of the datasets, it may take up to a few hours, you will get a confirmation email when done.
Step 4: Check the size of the datasets loaded
Once finished uploading, go back to your model and in the Overview tab check the number of records and conversions in the datasets. To build a model that makes statistical sense, the larger the dataset, the better. You need at least 1000 records and 200 conversions. Ideally, having 2000-3000 records is better. If you don't have enough records or conversions in your dataset, here is how to proceed:
First, select more dates. You can go back up to the past 6 months. HG Insights only stores 9 months of behavioral data and looks back 3 months from the dates you picked so you're limited to the past 6 months. You can only select dates 1 month apart, to make sure we count each lead only once.
If this is not enough, the next step is to choose a larger conversion definition. Beware, this basically means you will be building a different model, since the conversion definition is what the model predicts. We recommend going a step back in the funnel. For example, using the Closed Won definition instead of a definition CW > $ amount. You can also create a new custom definition, for example instead of using Closed Won, use Qualified Opps with a probability of > 20% let's say.
F.A.Q
What are the Advanced options parameters for in the training dataset?
This option removes from the training dataset any lead associated to a company who already converted before the simulated dates, meaning that it removes leads created after the creation date of the opportunity they're attached to. It is recommended to activate this option when building a model to predict new business opportunities , and to disable this option when predicting upsell or expansions.
Rebalancing ratio: the ratio between the number of non converted and the number of converters. A training set is usually created to obtain at least 20% conversion rate to avoid a class imbalance problem. the Rebalancing Ratio allows adjusting the conversion rate of the training dataset.
Ratio of 5 -> 20% conversion rate
Ratio of 10 -> 10% conversion rate
Do you exclude leads coming from our employees' email tests?
Yes, we exclude leads with the domain of your company from the training and validation dataset to avoid polluting the dataset and creating a bias in the model.
To go further ...
If you have a data science background or just curious about the methodology of creating a training dataset, using boosting and downsampling to fight class imbalance, continue reading.
What is the Class Imbalance problem?
A class imbalance occurs when the total number in a class of data (the converters here), is far less than the total number in the other class of data (the non-converters here) in a training dataset.
The minority class of converters is harder to predict because there are few examples of this class. This means it is more challenging for a model to learn the common traits of examples from this class, and to differentiate examples from this class from the majority class. Therefore the model would be biased towards the majority class. For example, your model predicts 90% of the time if the lead is going to convert or not, that's awesome! But if at 90% it predicts correctly the non-converters, then it means it never predicts correctly the non-converters, and does not help surface the very good leads, but only helps to reject the bad leads.
How do we work around Class Imbalance?
To fight the class imbalance problem, we use two balancing techniques to make sure the ratio between the class of converters and the class of non-converters is at least more than 2 out of 10 (= conversion rate of 20%)
boosting the minority class of non-converters by adding leads in the dataset who converted but were not created in the selected timeframe.
downsampling the majority class of converters by randomly selecting and removing non-converters from the training dataset.
All customer fit training datasets by default are created with a boosting, but the downsampling is controlled by the Rebalancing ratio parameter in the Advanced options section.