Prerequisites
You have access to the Data Studio
The Insights section in a Customer Fit model analyzes the relevance of each trait on the conversion to help you understand
your core Ideal Customer Profile (ICP), niche ICP and anti ICP
which computations and traits to use in the scoring model or in overrides
Looking at this section allows you to answer questions like:
In which industry do we perform best?
What is the DNA of our customers?
Are Australian leads really never converting like my sales reps are telling me?
You can analyze each trait on either the whole training dataset, which is a representation of your leads in your CRM, or on a subset of populations by going through the trees (see this section).
Use the Search bar to find a computation out of the 100+ available out of the box or that you created (e.g. Company Size, Funding, Role, Company Country etc), or just explore by scrolling down.
To see the definition of each computation, go to Computations on the main navigation bar on the left.
How to read the Insights graph?

The left hand side bar represents the overall population of leads (in the training dataset) by the different values of the computation.
In the image above, we are looking at the computation Company Size, showing that Enterprise companies (1000+ employees; in green) represent 18% of the leads.
The right hand side bar represents the population of leads who converted (in the training dataset). In the example above, Enterprise companies represent 23% of the conversions.
Because Enterprise companies are much more common among converted leads than in the general population, it means Enterprise companies are converting at a higher rate than the average (of the training dataset). Conclusion => Size = Enterprise is a trait with a positive impact on conversion.
On the other hand, the population of vSMB (1-10 employees) companies represents 11% of your leads but only 2% of your conversions, meaning they convert at a lower rate than the average.
Conclusion => Size = vSMB is a trait with a negative impact on conversion.
How to understand your ICP?
Core - your bread and butter traits. These represent the majority of your leads and typically convert like the average or better.
A core trait is probably not an eye-opener to you: this is most of your conversions. It is what you expect and is predictable. This is what you want the model to predict - those who will convert based on the traits of those who historically converted.
Anti - traits that are indicative of someone who doesn't convert
An anti trait is probably not an eye-opener either to you: you likely already avoid targeting them.
These leads sometimes convert, but are mostly not worth spending time on.
With Insights, identify all the red flags to look out for! Additionally, these traits are essential for your model to identify who to ignore.
Niche - leads with these traits convert well, but are fairly rare
A niche trait is when a small population of leads have this trait, but convert much better than the average.
When you see a niche ICP, ask yourself the following: can you generate more leads of that type? You may have overlooked them until now.
How to read the Lift graph?
What is the Lift?
A quick definition:
The lift of a category indicates how its conversion rate compares to the average.

It's a simplified visualization of the conversion rate of each trait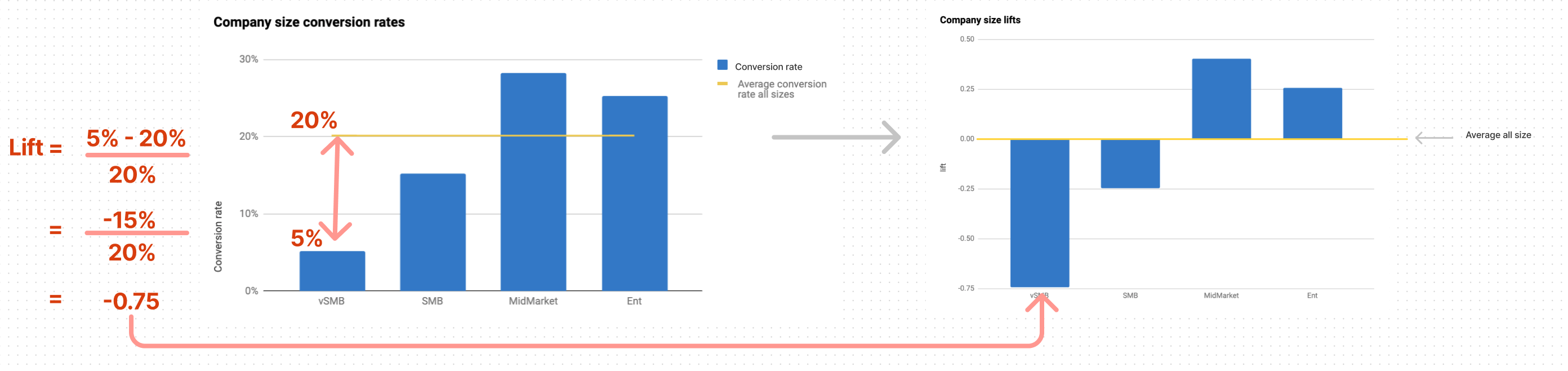
A positive lift essentially means that a category is more common among converted leads than the general population => this category converts better than the average.
How to read the lift graph?

when lift > 0 it means that a lead with this trait is more likely to convert
when lift < 0 it means that a lead with this trait is less likely to convert
when lift = 0 it means that the lead is as likely to convert as any other lead with or without this trait
Important note
The lift graph should not be read as an absolute measure. Rather, it needs to be compared to the volume of population we are looking at to ensure it is statistically significant.
Here is why: the lift is based on conversion rates, which depend on volumes. The smaller the volume, the more volatile the conversion rate may be (and the lift).
For example, you have:
3 conversions from Australia out of 5 leads from Australia -> 60% conversion rate, the conversion rate of the training dataset 20% -> lift of (country = Australia) = 2
300 conversions from the US out of 1,000 leads from the US -> 30% conversion rate -> lift of (country = united states) = 0.5
You could think lift = 2 is much higher than lift = 0.5, so let's bet our $10M marketing budget on Australia instead of the US... hmm but wait a minute: we are talking about 5 Australian leads, this is not statistically significant to conclude Australian leads are more likely to convert. These could just be outliers.
However, with 1,000 US leads, we confidently can say that a lift of 0.5 definitely means US leads convert better than the average.
This is why we display the next table to look into this statistical significance.
How to read the univariate analysis table?
This table shows the data where the two graphs come from: the volume of leads and conversions (both in percentage and absolute).
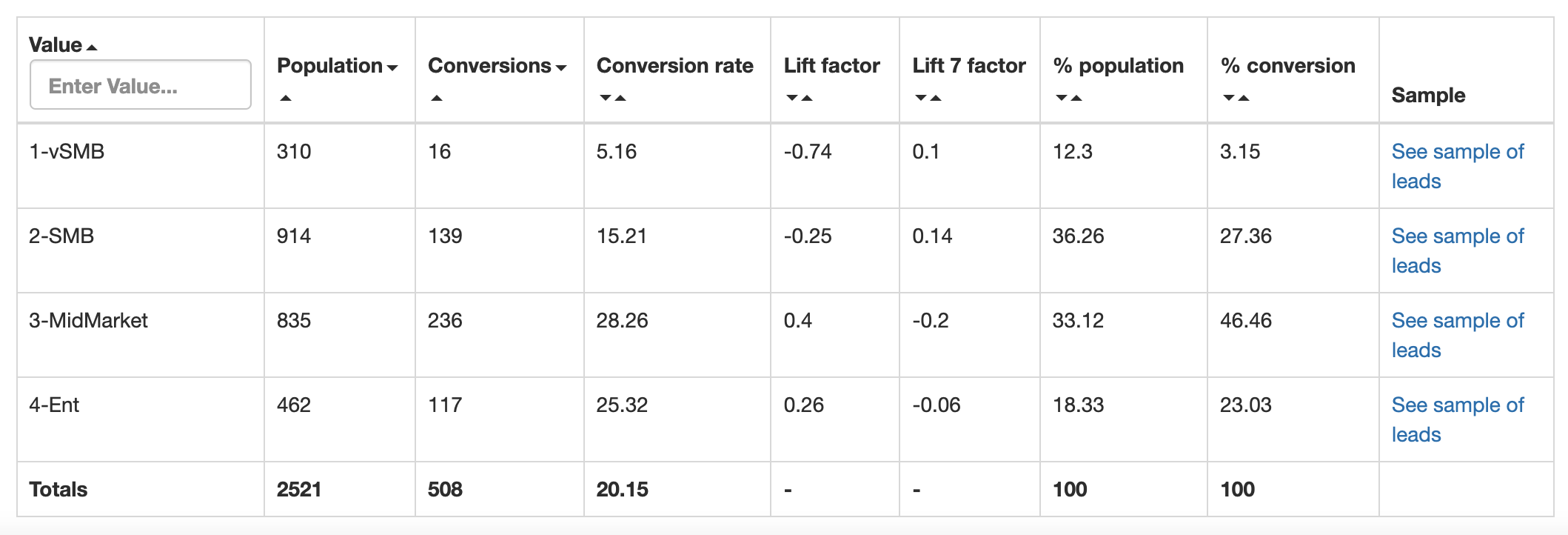
Population: number of leads (in the training set) where company size = [value]
Conversion: number of conversion (in the training set) where company size = [value]
Conversion rate: conversion rate of leads where company size = [value]
Lift factor
Lift 7 factor: it should be read "lift factor of non converters". Same as the lift described above but looking at the people without the trait.
% population: number of leads with the trait out of the total population. The sum of the column is 100.
% conversion: number of conversions with the trait out of the total population. The sum of the column is 100.
How to see these graphs, but filtered on a specific population?
Pre-requisites
You understand how the Decision trees work
The Insights tab does not allow to add filters besides including personal emails and leads without enrichment.
If you would like to look into the univariate analysis for a specific population, you will need to isolate this population. You can do that using the Trees and looking at the insights of each node.
For example: you'd like to know what company sizes perform the best but within the leads from US only, not all countries.
Go to the Tree tab
Create the following tree (on your test model, not your live model)
Split condition node 1: is_personal = 0
Split condition node 2: company_country = United States
Go to node 3
Click on View insights for this node
F.A.Q
How can I see this analysis on a more recent training set?
Just follow this guide about uploading a new training dataset