The Likelihood to Buy score is the result of the sum of all the activities of the person within the last 90 days, factored with a decay.
Each event performed by the person is associated with an Importance (weight) and a Lifespan (decay), which are the scoring rules. The events are defined in the Event mapping.
💡 HG Insights does not work with default scoring rules but instead automatically suggests custom scoring rules based on the analysis of the behavior of your past conversions 🤓. Smart, right?!
However, we may want to customize the weight of some events to improve the performance of the model and to suit your business need.
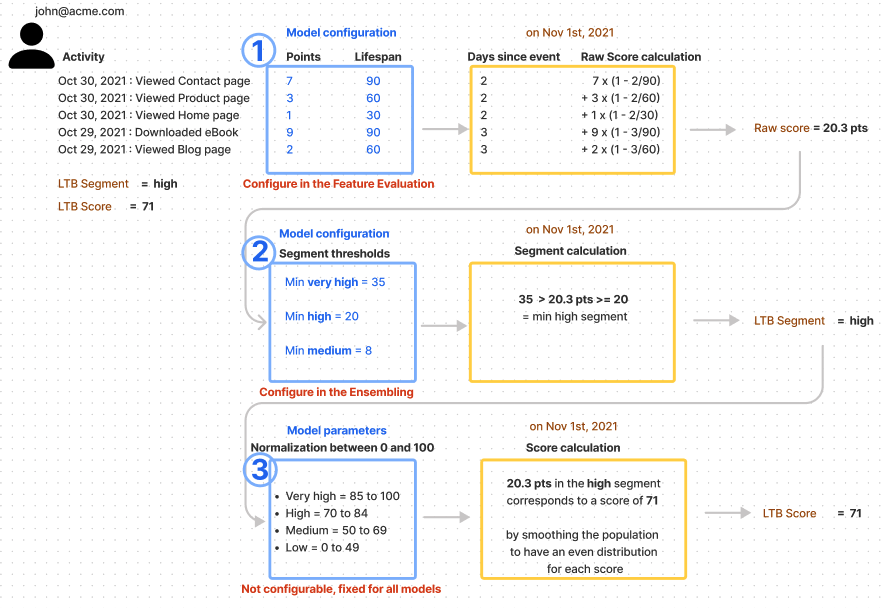
The weight of a specific event performed by a user in the Likelihood to Buy score (before the normalization, see 3.) is calculated based on its
Importance = the number of points this event represent on the day this event is performance
Lifespan (or decay) = the number of days the event will have a contribution to the Likelihood to Buy score. After the event lifespan, for example 90 days, the score of the user does not take into account this event anymore. If the user has only performed this event 90 days ago, this means their score goes back to zero. Learn more.
Therefore the contribution of an event at some point in time in the score is equal to
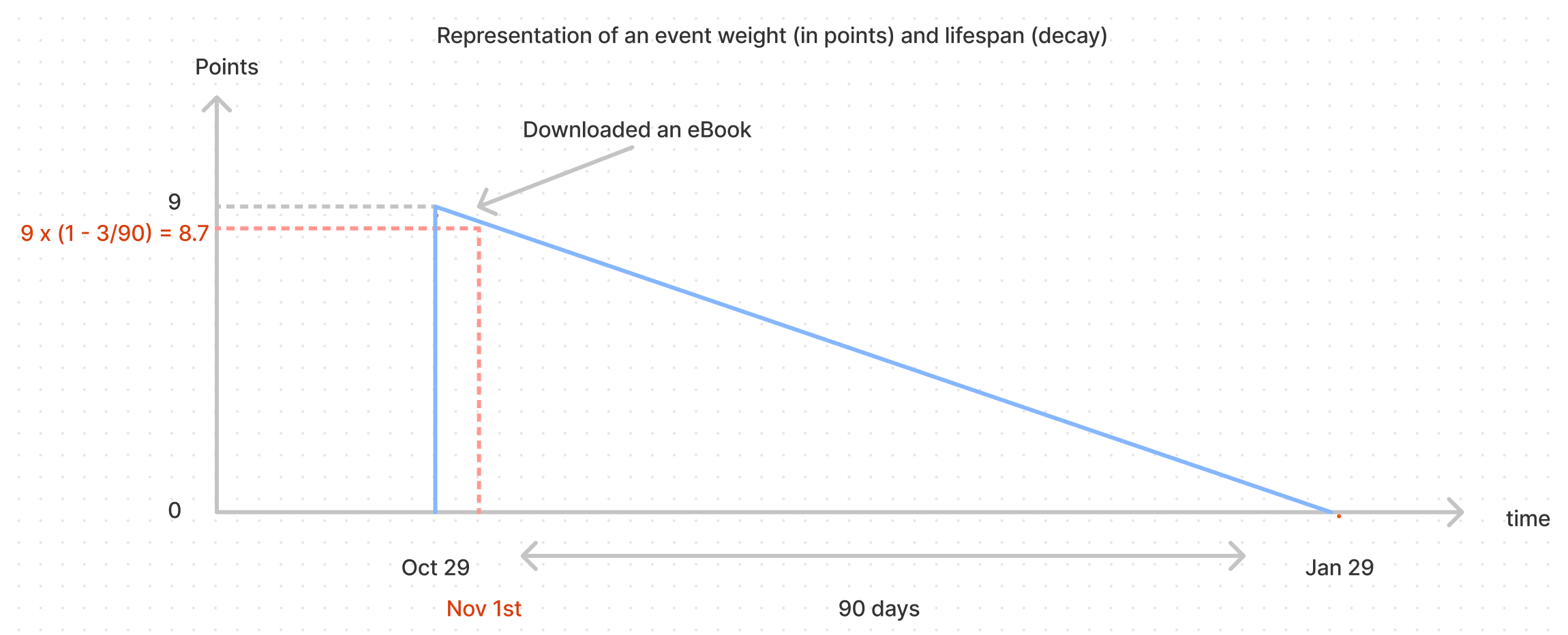
Example: If the user Downloaded an eBook 3 days ago, and this event is configured to be assiociated to 9 points and 90-day lifespan, then the weight of this event in the (pre-normalization) score is 8.7
If the Importance(points) and Lifespan of each event are automatically suggested based on the historical analysis of the level of activity of your past conversions, they can nonetheless be manually changed to tweak the model according to your Sales team feedback, your analysis, or business needs. This is configured in the Event weights tab of your model in the Data Studio. Learn more.
The pre-normalized score (or "raw score") is therefore the sum of all the events weights calculated as described above.
Now we need define what is the minimum raw score a user needs to have to be labelled as very high, high, medium or low Likelihood to Buy. The Segment thresholds allow defining these ranges of scores. They are configured in the Thresholds tab of your model in the Data Studio. These thresholds are unique to your model, which you can adjust to optimize the performance of the model or the volume of leads in each segment.
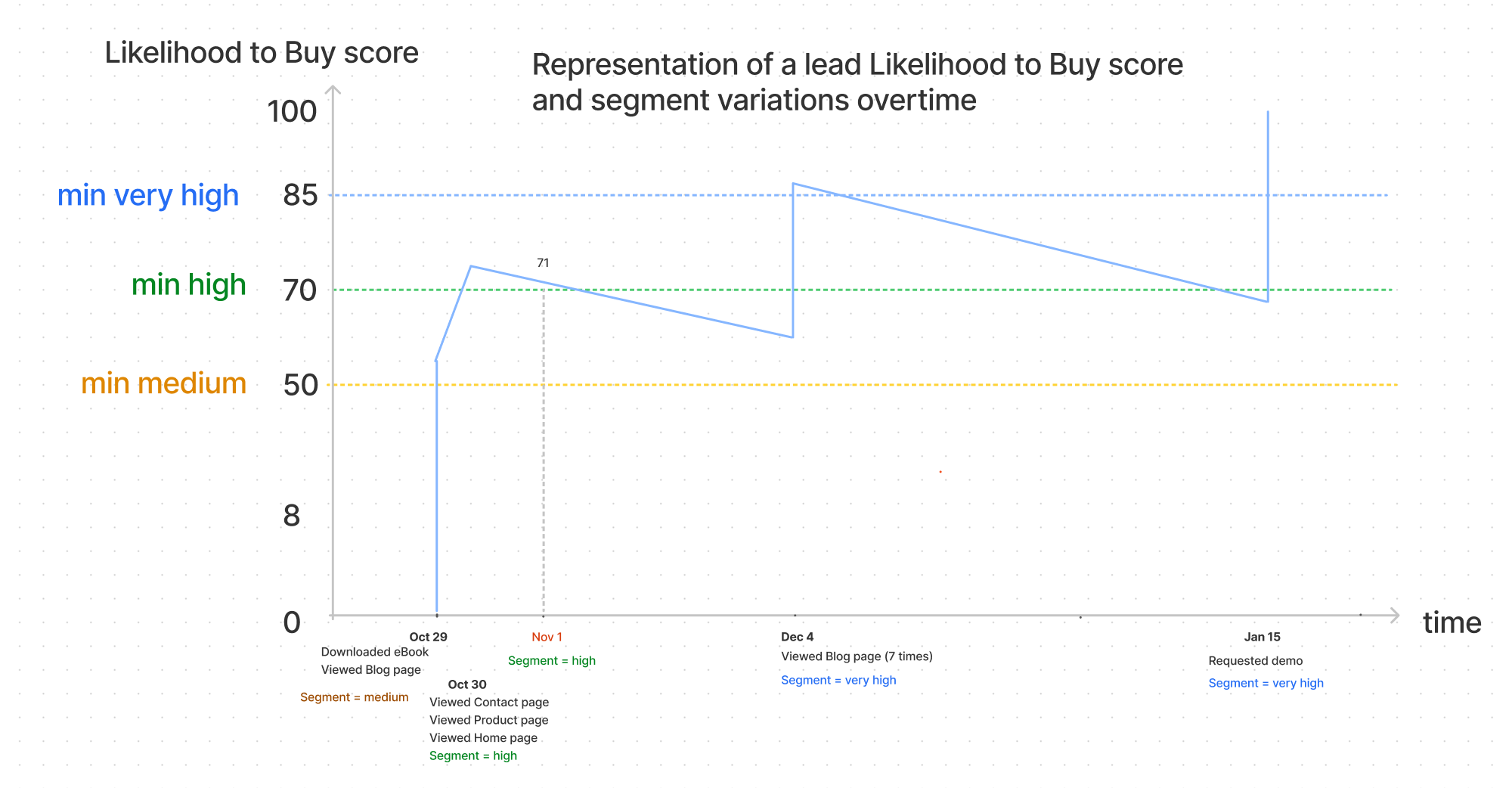
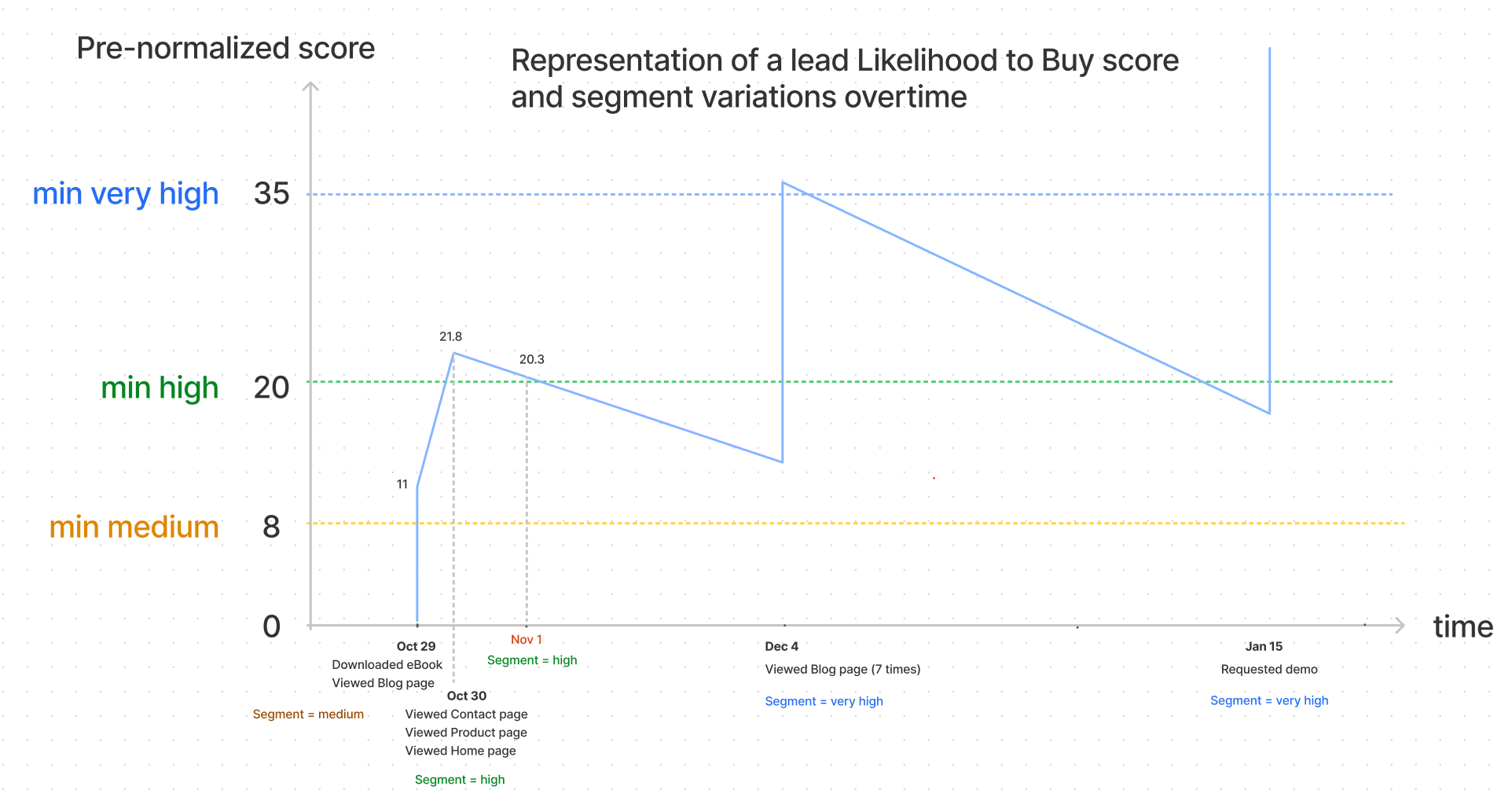
The graph below shows how the Likelihood to Buy score of a lead can evolve over time: when the lead performs an event, the score increases, and in the absence of activity the score naturally decreases based on the lifespan of each event.
This tells us that there are many different paths that can lead to a very high segment and that the lead can move from one segment to another quickly because of the lifespan taken into account.
The Normalization of the score between 0 and 100 makes sure the output of the model is a score between 0 and 100 and not the raw sum of points. Why? if the sum of all activities returns a score of 230, how would you know if 230 is a lot, or not? What is the maximum number of points someone could have? It is more likely for your Sales team to understand a score between 0 and 100, instead of -30 to 2569. This normalization is automatically done by the Data Studio and you do not need to configure it. It makes sure the output of the model is a score between 0 and 100 and the score range between the segment is always the same:
very high: 85 to 100
high: 70 to 84
medium: 50 to 69
low: 0 to 49
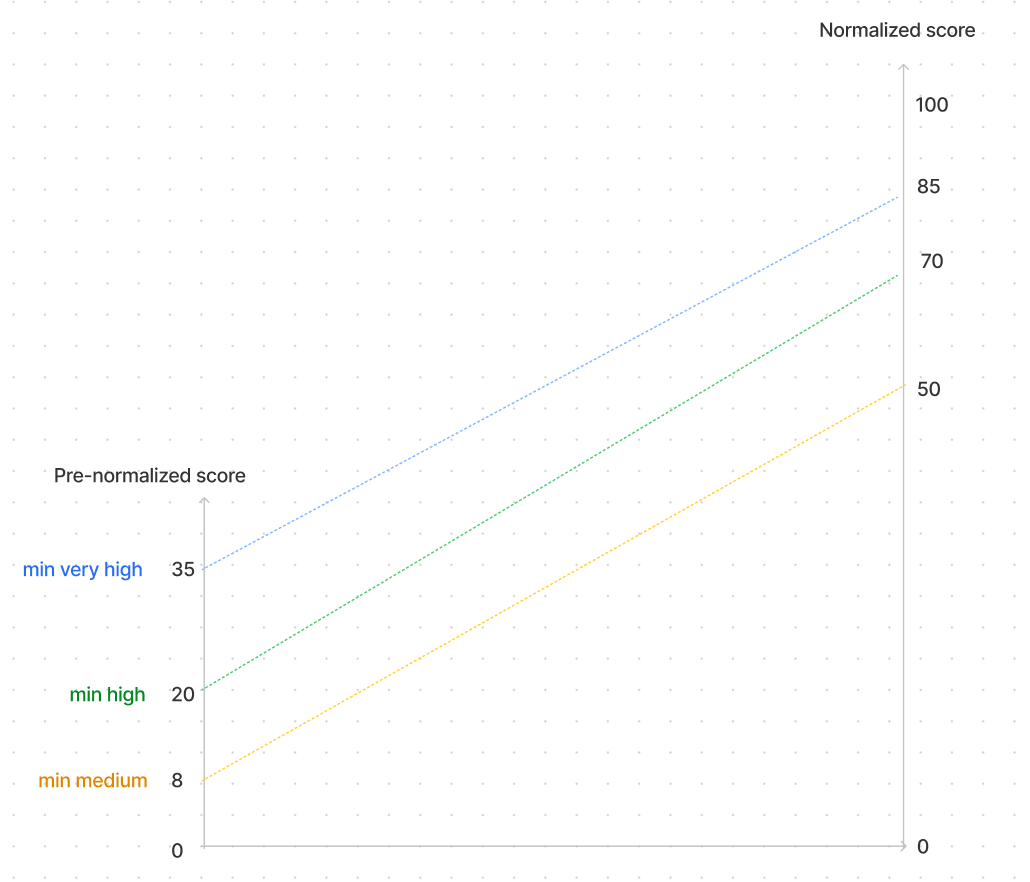
Here in our example, the thresholds were chosen as described in the step 2, and we have the following mapping between the internal thresholds and the model output thresholds (that you see in your CRM)

Why? Imagine if you were to explain to your Sales team that a Very high score is above 35, then High between 20 and 35 ... etc, and this would change every time you want to update the model. Well, good luck with that! So this is why we apply a normalization, it will translate the internal segment thresholds describe in step 2 into the external thresholds your team see in the CRM (0,50,70, 85)
How? a formula spreads the score before normalization into the normalized bucket. So that john@acme.com with a high segment and an raw score of 20.3, is at the bottom of the high bucket (the bottom being 20), and is matched as a 71 when normalized.